예시 데이터프레임으로 분류문제 모델링 하는 방법에 대해서 작성할 것이다.
예시 데이터 ) 금융상품 갱신 여부 예측하는 ANN(인공신경망)
필요한 라이브러리를 임포트 해준다.
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
Churn_Modelling.csv 파일을 이용하였다.
1. Nan 데이터 확인
데이터에 Nan 데이터가 있는지 확인을 한다.
Nan 데이터가 존재한다면, dropna() 를 이용하여서 제거한다.
2. 데이터 X, y 로 분류하기
데이터를 X와 y로 분리한다.
여기서 X 는 CreditScore ~ EstimatedSalary 컬럼이고
y 는 Exited 컬럼이다.
3. 문자열 데이터 수치 데이터로 변경
- LabelEncoder, OneHotEncoder
현재 예시 데이터프레임에서는 Gender 컬럼과 Geography 컬럼이 문자열 데이터이다.
문자열 데이터가 2개의 카테고리컬 데이터라면 레이블 인코딩,
3개 이상의 카테고리컬 데이터라면 원핫 인코딩을 하여서 수치 데이터로 변경한다.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
# 2개의 카테고리컬 데이터이기 때문에
# 레이블 인코딩
label_encoder = LabelEncoder()
X['Gender'] = label_encoder.fit_transform(X['Gender'])
# 3개 이상의 카테고리컬 데이터이기 때문에
# 원핫 인코딩
ct = ColumnTransformer([('encoder', OneHotEncoder(), [1])], remainder= 'passthrough')
X = ct.fit_transform(X.values)
dummy variable trap :
Geography 컬럼은 France, Germany, Spain 세개의 데이터로 이루어진 카테고리컬 데이터이다.
원핫 인코딩을 수행한 후, 맨 왼쪽 컬럼은 삭재해도 0과 1로 데이터를 전부 나타낼 수 있다.즉, France 컬럼을 삭제해도
1 , 0 => 독일
0 , 1 => 스페인
이렇게 맨 왼쪽 프랑스 컬럼을 삭제해도, 3개의 데이터를 모두 나타낼 수 있다.
이것을 dummy variavle trap 이라고 한다.
X 데이터를 dummy variable trap 을 하여서 젤 왼쪽 열을 제거해주었다.

4. 피쳐 스케일링
딥러닝은 무조건 피쳐스케일링을 해주어야 한다!
MinMaxScaler 를 이용하여서, 데이터를 피쳐스케일링 하였다.
from sklearn.preprocessing import MinMaxScaler
scaler_X = MinMaxScaler()
X = scaler_X.fit_transform(X)
5. 학습용과 테스트용으로 데이터를 나눈다.
데이터를 인공지능에 훈련 시키기 위해서 학습용과 테스트용으로 나눈다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.2, random_state= 0)
6. 인공지능 모델링
인공지능을 모델링하기 위해 필요한 라이브러리를 임포트 한다.
import tensorflow as tf
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Dense
- 모델링 변수 지정 (변수 : model)
model = Sequential()
- 레이어(계층) 추가
- 레이어의 갯수와 유닛의 수는 원하는 대로 설정한다.
# 첫번째 레이어 input layer 추가
# 유닛 6개, 전달 값 11개
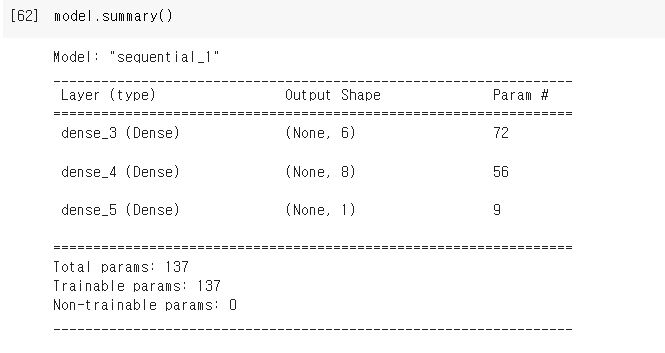
model.add( Dense(units=6, activation='relu', input_shape=(11,)) )
# 두번째 레이어 hidden layer 추가
# 첫번째 레이어에서 입력층의 크기를 정했으므로 생략 가능
# 유닛 8개, input layer에서 전달 받는 값 11개
model.add( Dense(units=8, activation=tf.nn.relu ) )
# 세번째 레이어 output layer 추가
model.add( Dense(units=1, activation='sigmoid') )
모델링을 한 후 summary() 를 하면 model summary 를 보여준다.
7. 컴파일(Complie) & 학습
모델링이 끝나면, 컴파일(Compile)을 해야한다.
컴파일이란, 옵피마이저(Optimizer)와 로스펑션(loss function 오차함수, 손실함수), 검증 방법 셋팅을 의미한다.
# 2개로 분류하는 문제의 loss 는 'binary_crossentropy' 을 설정한다.
model.compile(optimizer= 'adam', loss= 'binary_crossentropy', metrics= [ 'accuracy' ])
model에 fit 을 한 후 배치사이즈와 에포크를 설정해준다.
model.fit(X_train, y_train, batch_size= 10, epochs= 20)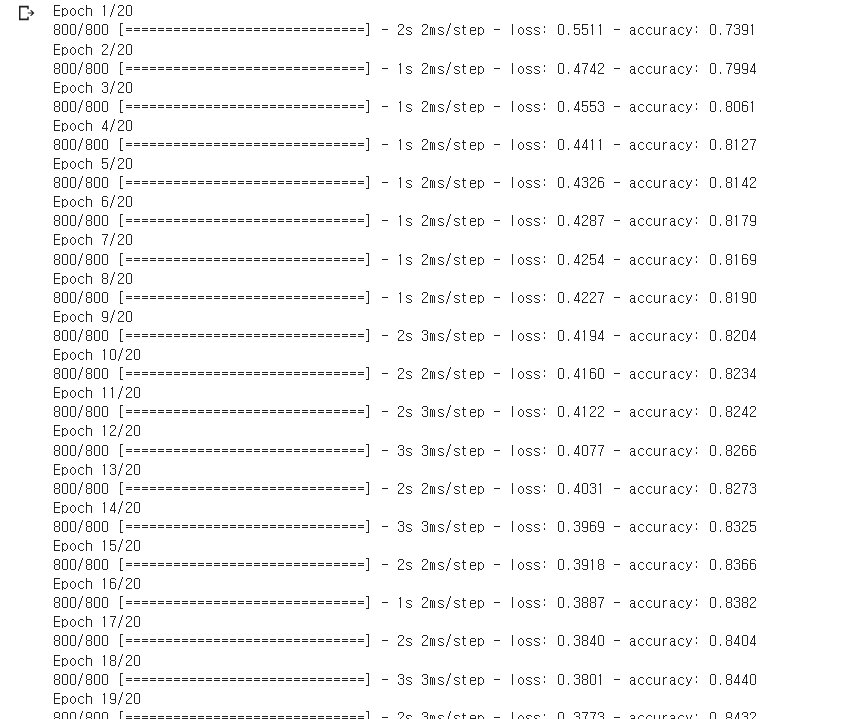
8. 평가 - confusion matrix, accuracy score
인공지능 학습이 끝나면, 인공지능이 얼마나 정확한지 평가를 한다.
# 학습이 끝나면, 평가를 한다.
model.evaluate(X_test, y_test)
# 컨퓨전 매트릭스를 확인하여, 어떤 문제를 잘 맞추고 못맞추는지 확인
from sklearn.metrics import confusion_matrix, accuracy_score
y_pred = model.predict(X_test)
# 예측값이 0.5 이상이면 1로, 0.5 미만이면 0으로 설정한다
y_pred = (y_pred > 0.5).astype(int)
만들어진 인공지능은 0.8535 의 정확도를 가지고 있다.

'Deep Learning' 카테고리의 다른 글
| Learning rate 를 옵티마이저에서 셋팅하는 코드 (0) | 2022.12.28 |
|---|---|
| 인공지능 모델로 새로운 데이터 예측하기 (0) | 2022.12.28 |
| Tensorflow, 회귀 문제 모델링 하는 방법 (0) | 2022.12.28 |
| Tensorflow - GridSearch 를 이용하여, 최적의 하이퍼파라미터 찾기 (0) | 2022.12.27 |
| Tensorflow - epoch 와 batch size 에 대한 설명 (0) | 2022.12.27 |